Automation (AI) is changing what is possible in evidence synthesis. Features that screen faster, extract data more efficiently and reduce manual workload are no longer theoretical.
In our previous article, we described a promising screening feature that was withheld despite achieving 98% mean recall, because performance in some reviews fell as low as 66%. That decision reflected something we had been building toward: a structured way to guide the responsible use of automation in evidence synthesis, determining whether an automation feature is appropriate for use, not just capable.
This article explores that approach in more detail and introduces a decision matrix we now use to make those judgements.
The transparency obligation
Evidence synthesis is built on transparency. Search strategies are documented, eligibility criteria is predefined, screening decisions are recorded and extraction methods are reported. This allows others to understand, reproduce and trust the evidence.
Introducing automation does not change that obligation. If the role of an automation feature cannot be evaluated systematically, explained to reviewers and reported in the methods, it does not meet the standards required for evidence synthesis.
From evaluation to implementation
Evaluating an automation feature is now more robust than it once was. Benchmarks and model cards have made it easier to understand how models perform, while frameworks such as Responsible use of AI in evidence SynthEsis (RAISE) have set important standards for evaluation and reporting.
But knowing how a model performs is not the same as knowing whether it should be used. That requires an additional step: deciding whether an automation feature is appropriate for a specific task, workflow and level of risk.
Our decision matrix is designed to support that decision.
The decision matrix
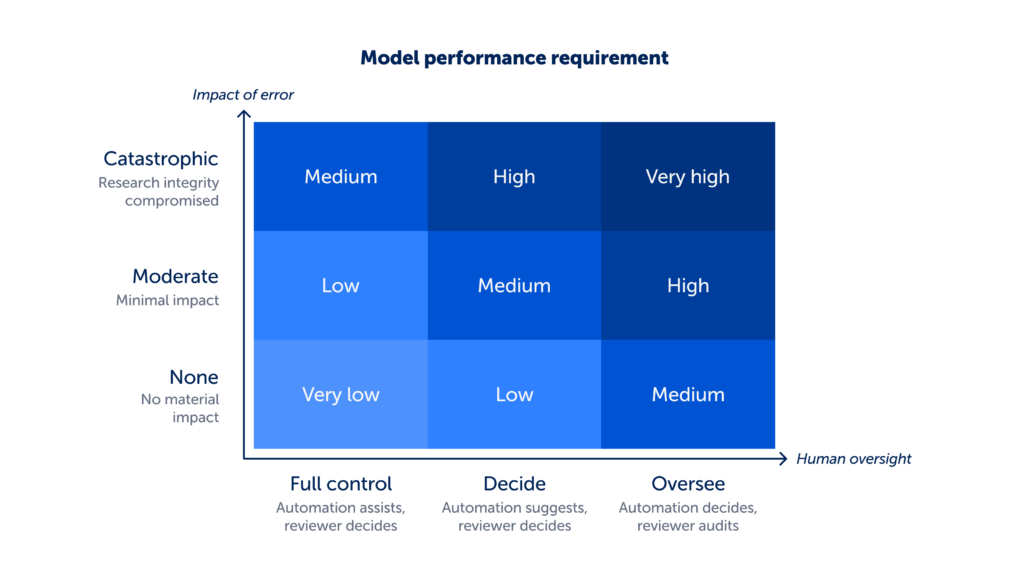
The decision matrix is built around three connected assessments:
- Impact of error: what is at stake if the task is performed incorrectly?
- Human oversight: what level of involvement do reviewers have in the workflow?
- Model performance: does the model perform well enough given the impact of error and human oversight?
Impact of error and human oversight work together to determine how much methodological responsibility the automation feature carries. In simple terms, this reflects how much the reviewer is relying on the automation feature to get things right. That responsibility, in turn, defines the minimum level of model performance required. Logically, as the impact of error increases and more responsibility is carried by the automation, the expected level of model performance correspondingly rises. Model performance is then assessed against the appropriate minimum threshold.
The matrix works in two directions. For reviewers, it helps determine whether an automation feature is appropriate for a given task. For tool developers, it provides a way to work backwards from model performance to determine which tasks a model is suitable for, and what level of oversight is required in the automation feature.
Impact of error
What is at stake if the task is performed incorrectly?
This assessment focuses on the consequences of getting the task the automation supports wrong. Impact of error is assessed based on the worst-case outcome, and classified as:
- None: no material impact on the research conclusions e.g. studies incorrectly sorted by relevance will not materially impact screening decisions.
- Moderate: minimal impact on the research conclusions e.g. extracting an incorrect non-critical data point will have minimal impact on conclusions made from the data.
- Catastrophic: compromises the research conclusions e.g. excluding a relevant study during screening could materially impact research conclusions.
Human oversight
What level of involvement do reviewers have in the workflow?
This assessment considers how easily errors can be detected and corrected, based on who makes the decision. Human oversight is classified as:
- Full control: reviewer makes all decisions and can easily detect errors e.g. AI sorts studies by relevance, but the reviewer decides inclusion.
- Decide: automation suggests and reviewer decides e.g. extraction values are suggested but must be accepted or rejected.
- Oversee: automation decides first and reviewer audits e.g. studies are automatically excluded or data flows into analysis.
Model performance
Does the model perform well enough given the impact of error and human oversight?
This assessment determines whether the model meets the level of performance required for the task.
Required performance is expressed in relative terms (e.g. high, medium, low) reflecting the level of performance needed given the task’s impact of error and degree of human oversight.
Performance is evaluated on datasets that are both large enough and representative of different types of studies, ensuring results are reliable and generalisable. Evaluation is conducted using task-appropriate metrics and confidence intervals, with emphasis placed on those most closely linked to identifying critical errors.
To support interpretation, model performance levels are considered alongside published evidence on human performance for similar tasks. We will share more about our evaluation approach in the next article in this series.
Applied in practice
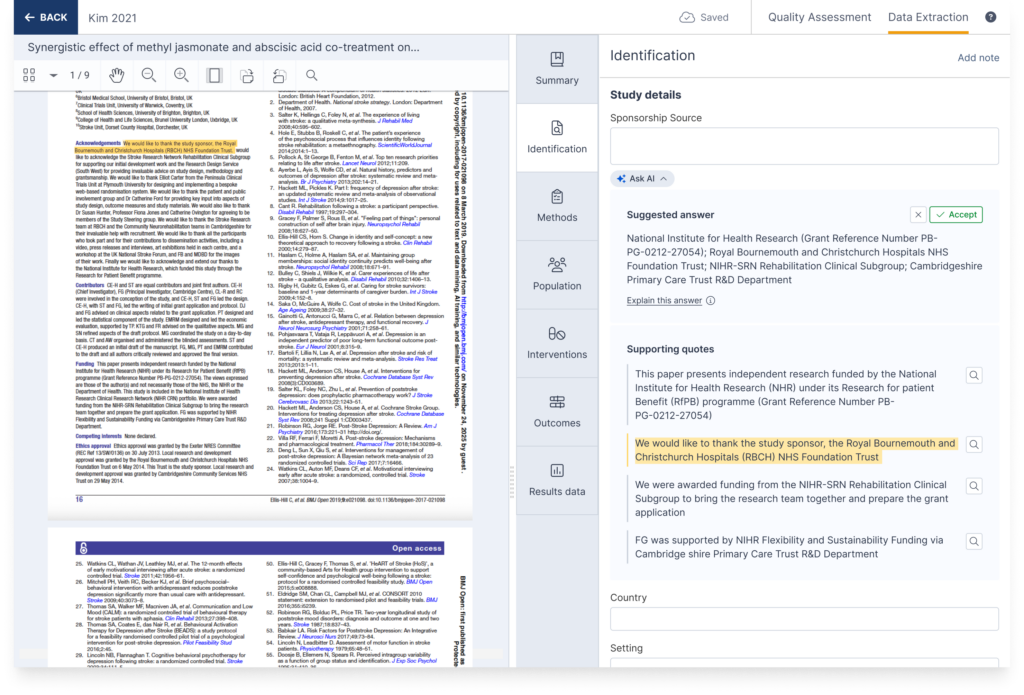
To illustrate how the matrix works in practice, consider the following example. We recently assessed an automation feature that provides AI-generated suggestions for the sponsorship source field during data extraction. A screenshot of this feature is shown below.
Using the decision matrix, we assessed the feature as follows:
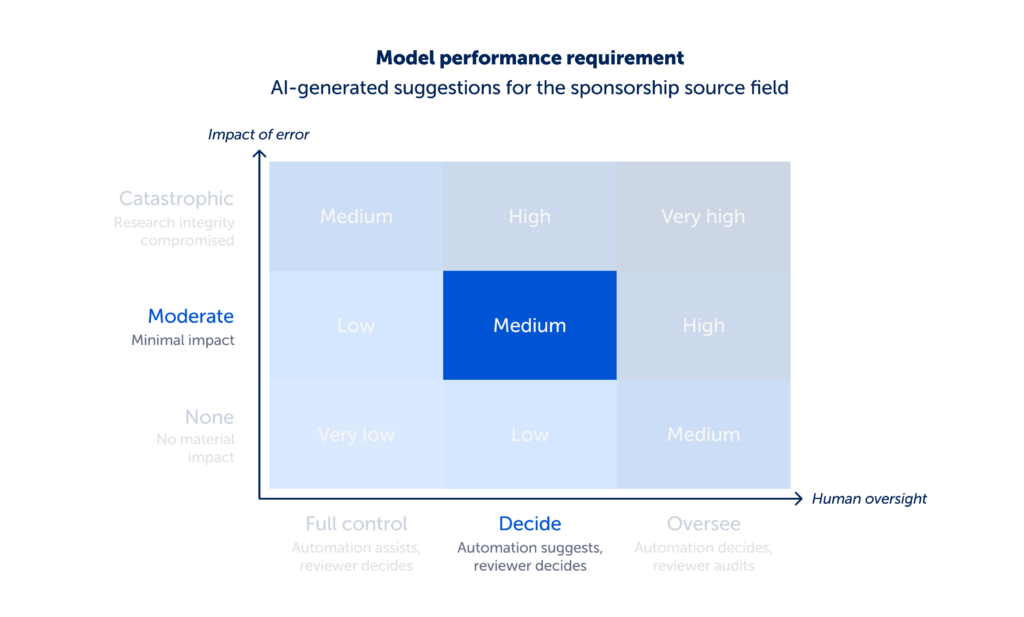
- The impact of error was moderate. An incorrect sponsorship source was deemed to have limited impact on review conclusions.
- The level of human oversight was decide. The feature workflow suggests values for the field with supporting quotes provided alongside the suggestion, the reviewer must actively decide to accept or reject each suggestion.
- This set the model performance at medium. We determined precision and recall were the most appropriate metrics to identify impactful errors. We set the minimum threshold for precision and recall at 80–85% to align with published methodological standards (Li et al 2019 and King et al 2024). The model surpassed this achieving 92.2% precision with 95% confidence interval range of 88.6%–95.7% and 100% recall on a representative dataset of 107 studies.
Based on the decision matrix assessment we chose to launch this feature in Covidence.
A contrasting example
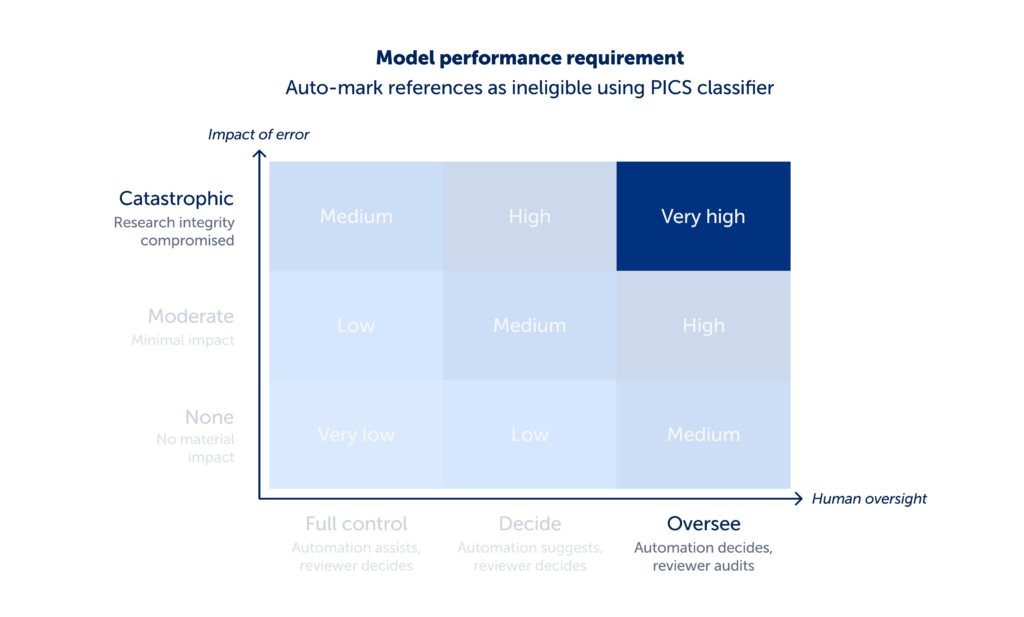
A contrasting example shows how the same matrix leads to a different decision. We assessed an automation feature that auto-marked references as ineligible using the PICS classifier, a model that predicts study eligibility based on structured inclusion criteria.
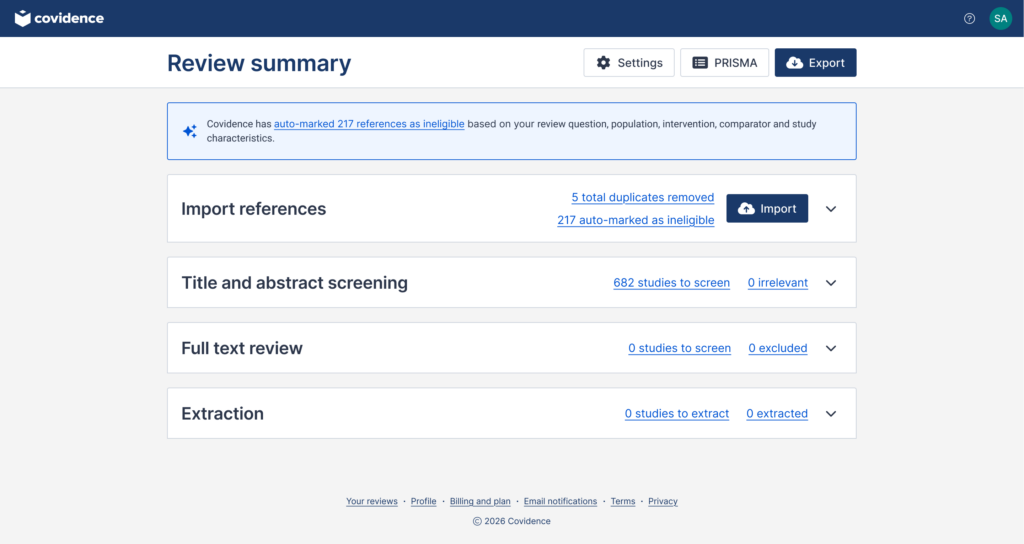
Using the decision matrix, we assessed the feature as follows.
- The impact of error was catastrophic. If relevant studies are incorrectly excluded at this stage, that can directly compromise the research conclusions.
- The level of human oversight was oversee. The automation makes the exclusion decision, and the reviewer would need to audit the exclusion list rather than actively make each decision themselves.
- This set the model performance at very high. We determined recall was the most appropriate metric to identify impactful errors. We set the minimum threshold for recall at 98% to align with community expectations (we surveyed Covidence users to determine this). While the model achieved an average recall of 98.6%, performance varied considerably across studies, ranging from 65.7% to 100%.
Based on the decision matrix assessment we chose not to launch this feature.
A record of decisions
We have used this decision matrix to evaluate every automation feature released within Covidence, across a platform used by thousands of active review teams. Features that meet these assessments, including relevance-based study sorting, automated RCT tagging and extraction suggestions, are released. Features that do not meet the grade are held back until their performance is acceptable.
The decision matrix is also finding application beyond Covidence. Cochrane has drawn on it to inform editorial guidance on acceptable AI use disclosures (this guidance is also endorsed by the joint AI Methods Group).
By providing a structured, transparent and reproducible way to set performance requirements, grounded in impact of error and human oversight, the decision matrix aligns with the principles that underpin systematic review methodology.
This is an evolving space. We expect this approach to be challenged, refined and improved, and we actively welcome that engagement.
At the same time, we recognise that automation feature adoption will vary. All automation features in Covidence are optional and can be turned off, allowing review teams to choose when and how to use them, or not use them at all, with confidence.
This is the third article in Covidence’s six-part series on AI:
- Part 1: Covidence’s approach to responsible automation (AI)
- Part 2: How Covidence decides what AI to release (and what to hold back)
- Part 3: Beyond evaluation: deciding when AI is appropriate in evidence synthesis
- Coming next: How we evaluate AI for evidence synthesis



