Determining whether an AI feature is appropriate for evidence synthesis requires a structured approach. In a previous article, we introduced a decision matrix composed of three assessments: impact of error, human oversight and model performance. Together, these define the minimum level of model performance required for an AI feature to be used responsibly.
This article addresses the next step: how to evaluate model performance in a way that demonstrates that threshold has been met. In evidence synthesis, this requires more than benchmark results. Performance must be measured against real-world review conditions, using metrics that reflect the consequences of error, and with attention to how performance varies across different contexts.
What follows sets out the approach we use in practice. It reflects what we have learned from building, testing and, critically, deciding when not to release automation.
What we compare against
To assess how a model is performing, you need a reference point to compare its output against. In evidence synthesis, defining that reference point is not straightforward.
Take data extraction. It is repetitive, high-volume work and a clear candidate for automation, but those same characteristics make it difficult to evaluate at scale.
For well-defined, bounded fields like sponsorship source, a curated benchmark works well as your reference point. We built one from 107 open-access studies, each independently extracted by two reviewers and resolved to a single consensus classification. Because each value reflects reviewer agreement rather than a single judgement, this provides a reliable, methodologically grounded reference point.
This approach however does not extend easily. First issue is scale. Producing curated benchmarks across the full range of field types, study designs and domains would require substantial ongoing effort. Second issue, coverage and process realism. A curated benchmark reflects a specific interpretation of what is correct, but in practice many extraction decisions depend on review context and protocol. A single benchmark cannot capture that diversity.
So to find a better option we looked at what the review process on Covidence already produces. Covidence holds a large and growing set of extraction decisions that have been independently assessed by two reviewers and resolved to consensus. This historical dataset* reflects how decisions are actually made in real-world reviews, across a wide range of contexts.
When assessing model outputs, we are now comparing those outputs against this historical dataset using an automated review step that flags uncertain cases for human verification. This focuses expert effort where it adds the most value, while ensuring the evaluation reflects performance across the full dataset. This approach provides both breadth and process rigour. It is not a fixed benchmark, but a continuously evolving reference point grounded in real review practice.
This methodology is still evolving. We are actively testing it across different review types and use cases, and we expect it to change as we learn more. We will continue to share how this develops as part of an open conversation with the community.
What we measure
Once a reference point has been established, the next question is what aspect of model performance should be measured. Terms like precision, recall and accuracy appear in almost every performance report.
- Recall (sensitivity): Of everything we needed to find, how much did we actually find?
- Precision: Of everything the AI flagged or suggested, how much was actually correct?
- Accuracy: Of all predictions, how many were correct?
Choosing the right metric depends on the failure you are trying to avoid. For a screening feature that removes irrelevant references, the critical failure is missing a relevant study, so recall is the priority. For extraction, the appropriate metric depends on the field. For single value fields such as study design, country or sample size, precision is often more important, as a plausible but incorrect suggestion can be accepted without being questioned. For multi value fields such as funders, outcomes or interventions, recall matters alongside precision, as missing information can be overlooked if the field appears partially complete.
Just as importantly, how performance is evaluated matters as much as which metric is chosen. Average performance can be misleading. Models rarely perform uniformly. Their performance varies across review types, topics, study designs and data quality. For example, an extraction model might achieve high average precision across a dataset, but perform poorly on studies with complex or inconsistently reported interventions. If those cases are also more likely to influence review conclusions, the risk is not captured by the average. In evidence synthesis, it is the lower bound of performance, not the mean, that determines whether a model is safe to use.
How we set the bar
Knowing how to measure performance is only part of the problem. The next question is what level of performance is sufficient.
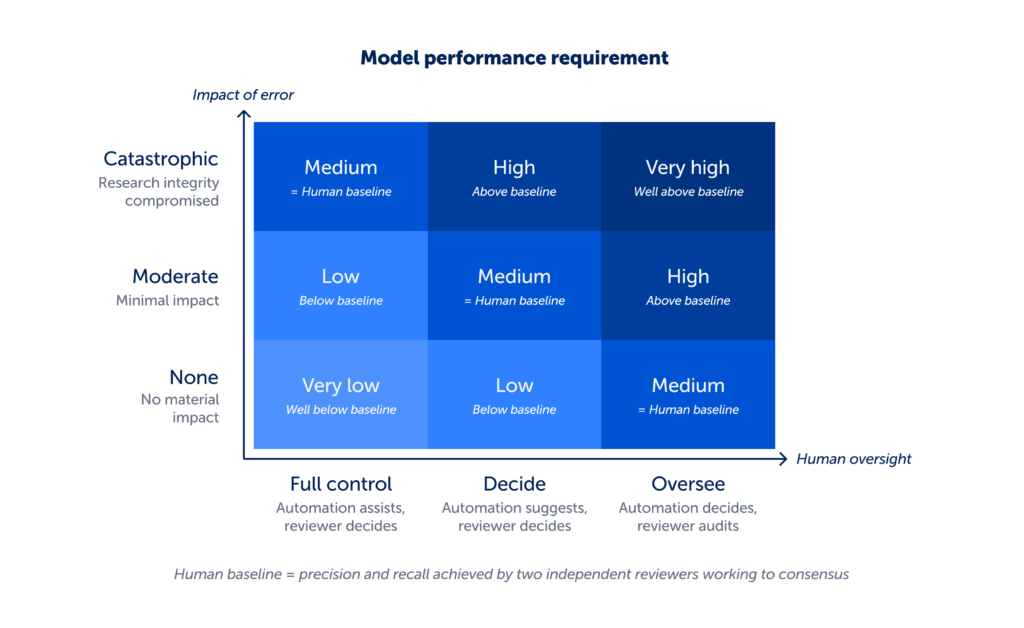
We start by establishing a human baseline: the precision and recall achieved by two independent reviewers working to consensus. For each task, we draw this from the most reliable source available e.g. published methodological studies, internal benchmarks, or structured user research.
Within the decision framework, this baseline defines the Medium threshold. A model performing at this level is operating comparably to an experienced reviewer pair. High sits above this baseline, and Very High higher again. Low and Very Low fall below it.
This approach often prompts a reasonable question. If systematic reviews are already built around human performance, why hold AI to a higher bar? The answer lies in error structure, not just error rate. Human errors tend to be varied and distributed, and are mitigated through independent review. AI errors are typically systematic. The same misunderstanding can repeat across many records. At scale, that repetition carries a different kind of risk.
For that reason, greater levels of automation requires stronger evidence of performance. The relationship between impact of error, human oversight and model performance makes this trade off explicit, so it can be examined and challenged.
How we stay accountable
Measuring performance is only useful if the results are visible. For every live AI feature in Covidence, we publish a model card, a transparent record of performance metrics, evaluation conditions, known limitations and guidance on appropriate use. Each card reports the metric the task demands, with confidence intervals that show the range of performance across review types, not just the average. Model cards are the transparency artifact RAISE recommends.’
Evaluation does not end at launch. We continue to monitor performance and update model cards as features meet new review types and configurations. If performance shifts, that is reflected publicly.
In summary, in evidence synthesis, model performance only has meaning in context. It affects what is included, what is missed, and how confident you, a reviewer, can be in the result. When Covidence reports model performance, you can trust that it reflects real-world review conditions, uses metrics suited to the task, sets thresholds based on the consequences of error, and is transparently updated as those conditions change.
This approach will continue to evolve. We share it to make our thinking visible and to support a more rigorous and transparent approach to evaluating AI across the field.
* A note on the historical consensus dataset. This work is about understanding how models perform, not training them on user reviews. We use aggregated and de-identified data to reflect real world conditions while maintaining strict protections over user content. Documents uploaded to Covidence are not used to train AI models, and maintaining the confidentiality of review data is non-negotiable. This is governed by our privacy policy and customer agreements.
This is the fourth article in Covidence’s six-part series on AI:
- Part 1: Covidence’s approach to responsible automation (AI)
- Part 2: How Covidence decides what AI to release (and what to hold back)
- Part 3: Beyond evaluation: deciding when AI is appropriate in evidence synthesis
- Part 4: How we evaluate AI models for evidence synthesis
- Part 5: AI won’t replace methods skills, it depends on them
- Coming next: How to justify AI tools to institutions
How do you feel about Covidence’s approach to automation (AI)? Share your perspective


