Practical advice for screening in Covidence
Screening studies is a central part of the systematic review process. Important decisions are made here that influence which data make it into the review. It’s a simple sorting process that needs a structured approach and rigorous methods. Sure, it’s repetitive. But it doesn’t need to be exhausting. Welcome to the Covidence guide to taking screening in your stride. Please step this way 🥾.
Two-step screening
The process of screening is split into two parts:
- title and abstract screening
- full text screening
Title and abstract screening helps to decide whether or not a study is eligible by looking at its title and abstract only. This first pass narrows down the list of potentially eligible studies that you will consider in step two, full text screening. This is shown in figure 1.
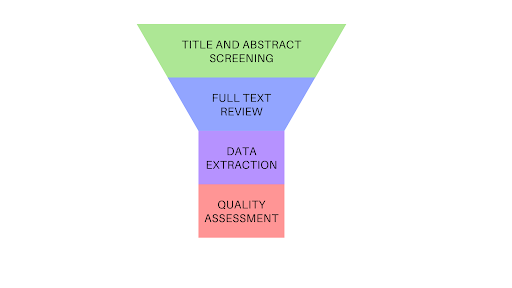
Full text screening is a deep dive into the study reports that you didn’t exclude at title and abstract screening 🤿. The reviewers will need to talk to each other about some of these decisions to reach agreement on inclusion or exclusion. In some cases where they cannot decide, they might also email study authors for additional information to determine eligibility 📧.
In this article we focus on full text screening. To provide some context, we’ll also cover what comes before (title and abstract screening) and look ahead to the data extraction and beyond.
First pass: Title and abstract
The number of references retrieved from a search can be daunting. In the process of deciding whether the identified studies are eligible for the review, your team will make important decisions and any of these can introduce bias. Good study selection requires a rigorous process and the first stage in that process is title and abstract screening.
In title and abstract screening, the first step is to plan and pilot-test the process. Next, studies are screened and a decision is made either to include or exclude them. Finally, the decisions are logged so that they can be written up in the methods section of the review ✍.
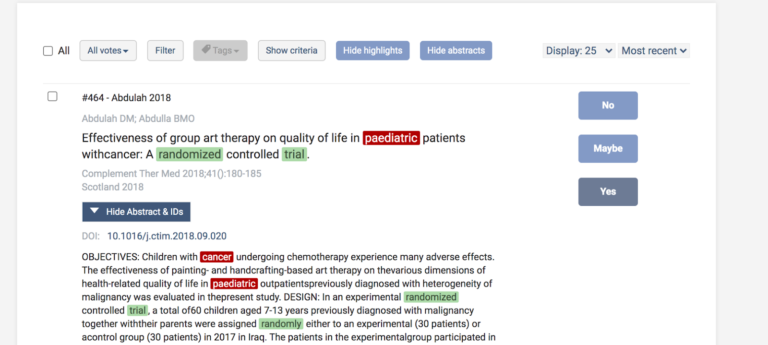
During title and abstract screening in Covidence, reviewers vote on whether a study is eligible for inclusion by selecting ‘yes’ (the study is eligible), ‘no’ (the study is ineligible), or ‘maybe’ (eligibility is unclear). In most cases, reviews are configured so that two reviewers vote independently on each reference. If both reviewers vote ‘yes’ or ‘maybe’, the reference goes forward to full text review. If both reviewers vote ‘no’, the reference is taken out of the running and moves to the ‘Irrelevant’ list. So far, so straightforward 🙏.
If two reviewers disagree with each other – one ‘Yes’ or ‘Maybe’ vote and one ‘No’ vote – the reference goes to the ‘Resolve conflicts’ list. At this point, the review team will implement its agreed conflict resolution process. Covidence keeps this process simple and intuitive. Reviewers receive alerts about the conflicts so that they can resolve them quickly and efficiently.
Covidence has a keywords tool that speeds up screening. Review teams can input words that are likely to indicate inclusion or exclusion. These words are then highlighted in the screening list to help keep reviewers focused on the information they need to look at to cast their votes 👀.
Planning and pilot-testing reduce the amount of disagreement between reviewers but they will not remove it completely. Often, disagreement can be resolved by discussion until the reviewers reach consensus. If that is not possible, the disagreement should be referred to another member of the team to make the final decision.
Second pass: Full text review
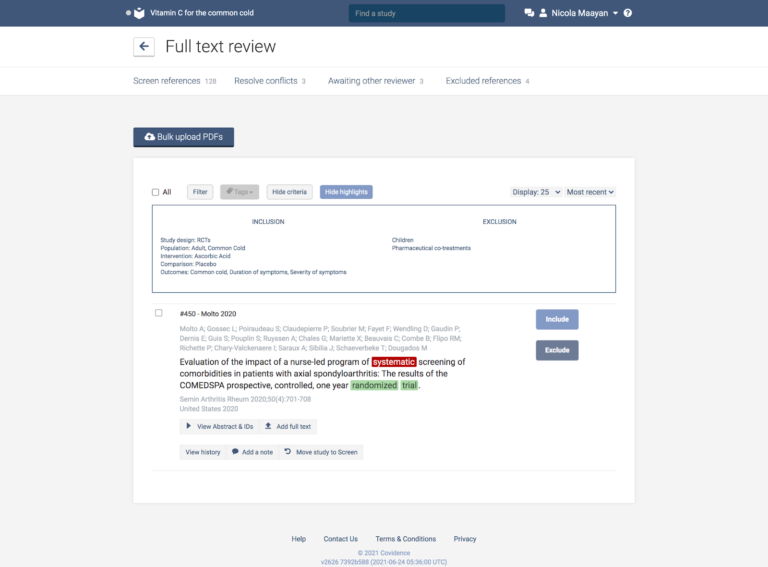
- The full text review examines in detail the studies that were not excluded at the first pass. There is no ‘maybe’ option for the reviewers at this stage: it’s crunch time.
When your studies move to the full text stage of your review, Covidence automatically adds the PDFs of open access articles. 🙌 To add the rest, there are two options:
- If the article is already saved to your device, simply drag and drop it into your review or use the ‘Upload full text’ button to choose the relevant file.
- If you don’t already have the articles, you can retrieve them using your reference manager and import them in bulk.
And if you’re not sure whether you have access to a particular article via your institution you can click the DOI link in Covidence to find out.


Working through a list of records, reviewers vote either to include or exclude each of them, based on information contained in the full text of the study report. This means that the reviewer can look at the methods used in the study and check, for example, that the assignment of participants to the treatment and control groups was random. As before, reviewers cast their votes by considering whether or not the studies meet the inclusion and exclusion criteria. These can be conveniently displayed on screen above the list of references in Covidence.
In this way, a reference can be excluded as soon as it fails to meet one of the criterion, for example:
- Study was not a randomised trial ⛔
- Study had the wrong comparator ⛔
- Study had the wrong patient population ⛔

Systematic reviewer pro-tip:
Save time by listing exclusion criteria in order of importance and working down the list.
Covidence records one exclusion reason per study. If each reviewer gives a different reason, this sends the reference to the ‘Resolve conflicts’ list. Here the review team will implement its agreed conflict resolution process in order to reach agreement on the exclusion reason.
Reaching consensus
Study screening is usually done by two reviewers working independently 👩🏻💻👨🏾💻. If their votes agree, the reference either goes forward to data extraction (two ‘yes’ votes) or is excluded from the review (two ‘no’ votes).
If the reviewers’ votes do not agree – and this can be on whether or not to include the study, or on the reason given for excluding it – the reference moves to the ‘Resolve conflicts’ list. Again, the reviewers must reach consensus. And again, if they cannot, the disagreement is referred to another member of the team, who has the final say.
In Covidence, reviewers are blinded to the voting of others as they work through the references. This is to prevent their decisions being influenced by those of their colleagues. Once all the votes are in and the conflicts are resolved, Covidence automatically populates a flow diagram with the decision data. This documents the flow of studies through the review and follows the reporting standards for systematic reviews as set out in the PRISMA statement ✅.
Covidence enables users to add tags and notes to references and to use these to filter and sort lists. If, for example, you have sent a request for information to several study authors, you can add a note to the relevant references to inform your colleagues 🙋. You could also add a tag to those records and use it to quickly produce a list of all the references for which additional information from study authors has been requested 🔖.
Measuring agreement
Covidence uses Cohen’s kappa to calculate the level of agreement among reviewers (known as the interrater reliability). Interrater reliability statistics are used to catch ‘coder drift’, the tendency for reviewers to deviate from the process as it becomes more familiar to them. Pilot testing of screening questions and training for reviewers can improve interrater reliability, which can be monitored throughout the screening process.
Extracting the data
The data in the selected studies now need to be extracted in a way that is structured, consistent and reliable. Covidence provides customisable data extraction forms to help you breeze through data extraction. Prefer to build your own form from scratch? That’s fine too. From here you can export data to a CSV file and from there to wherever you like to do your data analysis – the choice is yours 📊.
In conclusion
A structured and disciplined approach is key to the success of screening. A large amount of material needs to be sifted systematically and the methods reported accurately and transparently. Covidence saves time on the repetitive tasks of screening and helps you complete your review quickly and efficiently. Sign up for a free trial of Covidence today!


